糞コードをリリースすることの是非みたいな発言をXで見かけたので私見を纏めておく。
糞コードの問題は、理解するのに時間が掛かるとか、改修が困難とか、バグを出しやすいとか色々と言われるけど、纏めるとランニングコストが高いと言うことになる。単純にコードの保守性だけの問題では無くて、処理が最適化されていないために多くのコンピューターリソースが必要となるといった事も含まれます。
ランニングコストが高いと何が不味いのかを、簡易的にグラフにしてみた。
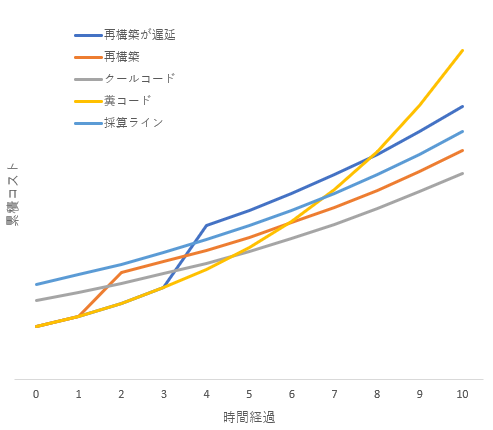
時間経過とともに機能が追加されたりデータが増えたりするため、システム規模は日に日に大きくなり、累積コストは指数的に増加していきます。糞コードは初期コストが安くても運用コストが高くなります。対してクールコードは初期コストが高くても運用コストが低く抑えられています。初期は糞コードの方が運用コストが低く済んでいますが、いずれクールコードと逆転するわけです。
糞コードの収益性が悪いだけなら良いのですが、場合によっては採算ラインを超えてしまう事が起こります。独占企業なら問題にならないかもしれません。ですが競合他社が居る場合、運用コストの高さは長期的にビジネスの継続を危うくするわけです。
糞コードは後で書き換えれば良いという主張もあります。ビジネスとして継続する為に、システムを再構築してクールコードに書き換えるわけです。ですがこれは開発コストを二重に負担しているので、コストが大幅に増えて収益を圧迫します。
特に新規のビジネスの場合には資金的にも人員的にも余裕がないため、実際には糞コードの再構築は後回しになりがちです。再構築が遅延すると、その間にコードもデータも増えていくため、再構築にかかるコストがより大きくなります。最悪の場合、再構築を行うと採算ラインを越えるため出来ないが、このままだと運用コストが採算ラインを越えるため放置も出来ないという、詰んだ状態に陥るわけです。
以上のことから、糞コードのリリースについて三行に纏めておく。
- 時間的な制約から糞コードをリリースする場合はあり得る。
- だが糞コードは最小限にし、速やかに改修しておく必要がある。
- 糞コードの放置はビジネスを終わらせる時限爆弾となり得る。














